spinlock vs mutex performance
4 rounds, no holds barred

Recently I had to do some fine tuning of a very tight loop synchronization in one of the Node.js addons I work on (https://github.com/mmomtchev/exprtk.js). I ended trying lots of things, reading various opinions, debating with people and producing a couple of PRs that are currently stalled in Node.js PR and libuv (https://github.com/libuv/libuv/pull/3429).
While researching the subject, I did find a ton of information online — I compiled a good list that you can check at the bottom of this story. As most of it is very contradicting, I decided to check it all for myself.
Intuitively, I was thinking, using a spinlock should be faster if the average time holding the lock is shorter than the cost of a context switch.
Turns out, there is some truth to what I was thinking and there is some truth to every single opinion in the list at the bottom, but most of them are also missing at least some crucial aspect.
I tried, as much as I could, to implement a benchmark that is indicative of real-world synchronization instead of some synthetic test meant to demonstrate worst-case scenarios. All the code used in this story can be found here:
The benchmark simulates an arithmetic computation in a loop with a configurable unsynchronized part and a critical section repeated at each iteration. Its result is the number of achieved iterations compared to the impossible ideal case where all threads work all the time without ever waiting — expressed in % from 0 to 100.
while (running) {
do_local_work();
lock();
do_shared_work();
unlock();
} Hyperthreading is disabled. Enabling it does not really impact anything except that the TTAS lock starts performing better compared to the TAS lock with 8 threads — there is a dedicated section towards the end of the story discussing the different types of spinlocks.
I have included four different spinlock protocols — you can read more about them at the bottom — only to prove that (most of the time) spinlock protocols do not really matter in the real world. You can check spinlock.h for the different algorithms used or refer to [3] and [4]. Their performance is so similar, that they can be used to estimate the statistical error in my tests.
On the mutex side, things are much simpler — there is the OS-provided mutex [6] and no one ever bothered to implement something else before the Apple Webkit team in 2015 [7]. Their locking protocol is also used in Rust. They seem to imply that their mutex outperforms the OS-provided one by a wide margin, but, alas, it is too tied to Webkit to be meaningful outside of it. This mutex protocol, called the WTF::Lock (where WTF stands, obviously, for Web Template Framework) was also evaluated by the Gecko team who concluded that the speedup was significant only on macOS [8]. Their work probably merits a story of its own.
So here we go, first round, 99% unsynchronized work and 1% critical section, graphing the results as a function of the cycle length with 4 threads (1 core = 1 thread, aka no one is bothering us) and 8 threads (1 core = 2 threads, contention case, aka people are waiting outside):
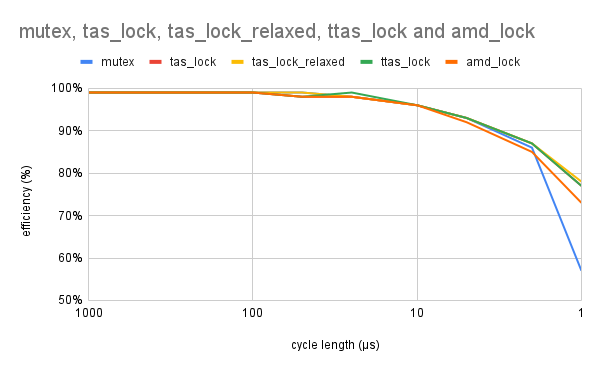
This test reflects most real-world situations. This is the typical case where a fair amount of work is done per cycle and then a shared data structure is accessed at each iteration. As expected, there is no performance gain from using a spinlock until the cycle length starts approaching the cost of locking a contested mutex (and thus performing a context switch)— the difference is not significant until 2µs — which translates to a whopping 500,000 cycles per second.
All this somewhat meager gain is thrown out of the window once the CPU time lost spinning is factored in:
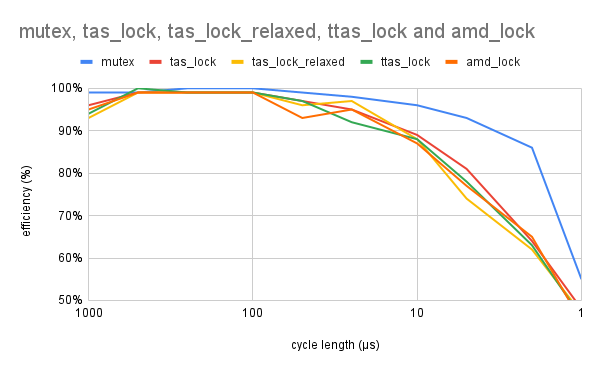
With 8 threads on 4 cores, there is always someone waiting. Here, the mutex allows another thread to step in when waiting, while the spinlock simply wastes the CPU time.
Linus Torvalds makes a very good point, spinlocks are next to useless in the userland [2] [5].
The next one, 90% local work and 10% critical section is also a typical real-world case. It is indicative of a pool of workers performing a more complex task while holding the lock —like traversal of a tree or LRU expiry for example:

As the lock becomes more and more contested, the threshold where the spinlock outperforms the mutex starts rising. However once we factor the wasted CPU time, the situation becomes disastrous on the spinlock side of town:

The effect Linus describes in his email, already noticeable in the previous test, is now obvious. The scheduler does not know that the thread is spinning — all it sees is a very busy thread using up its full quanta. Thus cycle lengths close to the Linux scheduler quanta produce terrible results — because threads holding a spinlock are being scheduled out — while threads spinning in vain are being scheduled in.
The third one, 75% local work and 25% critical section is an extreme case where a significant amount of work is performed while holding the lock.

Now, there are limits to what is possible with a mutex. If a mutex is highly contested and the average work cycle length is close to the cost of locking a mutex, performance will obviously be close to zero. If you have such a significant amount of work to do in your critical section at every iteration — there is only one way out — and it is to have longer cycles. Hold the mutex longer, do lots of work, release it, wait longer. This way you can spread the cost of locking a contested mutex. Or use a spinlock. Or better not:
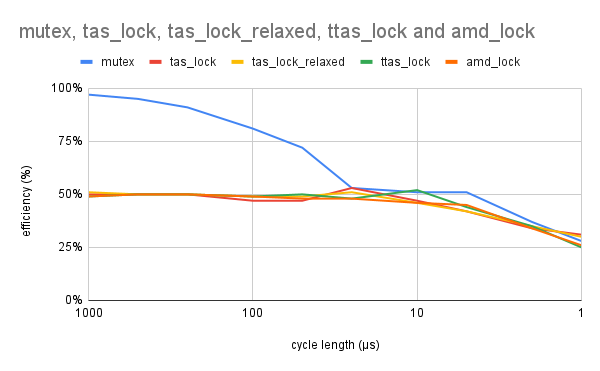
Here you see what Linus meant by “do not use spinlocks in userland unless you know what you are doing”. This time the magic bullet called spinlock went right through our foot even if we were aiming at the sky.
The last one, 25% local work and 75% critical section, is the pathological case. It is included because it is indeed a very stressful test for the locking mechanism — and most other authors I have cited here use those kind of extreme tests. In my opinion, this test does not reflect any real world situation. But still:


As expected, in this case performance is abysmal across the board. Once again, the mutex starts falling behind once the cycle length starts approaching the cost of a context switch and once again the spinlock performs very poorly if there are lots of ready-to-run threads available to the scheduler.
Conclusions
So when do we use a spinlock instead of mutex?
- If you are simply incrementing a single counter, or doing anything else with a scalar value, use
std::atomic(or the equivalent C mechanism using compiler intrinsics), it is there for a reason and it is a hardware solution that cannot be matched by any software mechanism; - If you are running a very tight loop where one or more values are shared across the worker threads and you never do anything more than a couple of assignments in the critical section, a spinlock may outperform a mutex. You must also make sure that no more threads than the number of physical cores will contest this spinlock. This case includes well-implemented O(1) queuing;
When in doubt, or in all other cases, use a mutex.
Locking and unlocking an uncontested mutex is a very fast operation, measured in nanoseconds. It is when the mutex starts being contested, that these times increase hundreds even thousands-fold.
If the mutex is rarely contested, optimize the length of the critical section.
If the mutex is highly contested, try to consolidate iterations.
A note on different spinlock protocols
Spinlock protocols is a common research subject in academia [3] and there are lots of very good and advanced mechanisms out there, starting with the most basic ones, the TAS lock and the improved TTAS lock.
In most practical cases there is almost no difference between these protocols, but in some particular situations the difference can be measured in orders of magnitude.
For example, a famous C++ pundit [1] is educating everyone about the proper way to implement a spinlock with a show case of “good” vs “bad” spinlocks. Do not immediately jump on this bandwagon. The differences between a TAS and TTAS spinlock go beyond the scope of this story — check what he is saying because he is right and his blog post contains a very good introduction to the problems of cache coherency — but basically it comes down to this: a TTAS lock has an (almost) constant locking time without regard to the number of waiting threads. On the other side, the locking time of a TAS lock increases linearly with the number of waiting threads. With 200 threads the TTAS lock is orders of magnitude faster, but if you never have more than 1 or 2 threads waiting on the same spinlock, then the simple TAS lock is in fact slightly faster. Should you have 200 threads waiting for a huge critical section on a single spinlock and still talk performance, is up to you. My benchmarks show that TTAS outperforms TAS starting with 8 threads on 8 cores. Hyperthreading makes it even more obvious. I was unable to reproduce his benchmark where the TTAS was outperforming TAS with only 2 threads and I don’t think it is even possible since the problem of the TAS lock involves at least one thread that owns the spinlock and at least two other threads that are actively spinning.
- Correctly implementing a spinlock in C++, Erik Rigtorp
- No nuances, just buggy code (was: related to Spinlock implementation and the Linux Scheduler), Linus Torvalds
- Survey of Spin-based Synchronization Mechanisms, Sandeep Kumar
- Measuring Mutexes, Spinlocks and how Bad the Linux Scheduler Really is, Malte Skarupke
- Mutexes Are Faster Than Spinlocks (response to the previous article), Aleksey Kladov
- Futexes Are Tricky, Ulrich Drepper
- Locking in WebKit, Filip Pizlo
- on mutex performance and WTF::Lock, Nathan Froyd
